Enhance your academic content’s credibility and make navigation of your articles easier on WordPress with these essential plugins.
Source: Meet Academic Standards With These Essential WordPress Plugins For Scholarly Content

The 6th incarnation of Elmer's blog
Enhance your academic content’s credibility and make navigation of your articles easier on WordPress with these essential plugins.
Source: Meet Academic Standards With These Essential WordPress Plugins For Scholarly Content
In general the plan is to scrape the site to a vector database, enable embeddings of the vector db in Llama 2, provide API endpoints to search/find things.
The challenge is to wire together these technologies and then figure out how to get it to play nice with Drupal. One possibility is just to build this with an API and then use the API to interact with Drupal. That approach also offers the possibility of allowing the membership to interact with the API too.
In the world of data, textual data stands out as being particularly complex. It doesn’t fall into neat rows and columns like numerical data does. As a side project, I’m in the process of developing my own personal AI assistant. The objective is to use the data within my notes and documents to answer my questions. The important benefit is all data processing will occure locally on my computer, ensuring that no documents are uploaded to the cloud, and my documents will remain private.
Demystifying Text Data with the unstructured Python Library — https://saeedesmaili.com/demystifying-text-data-with-the-unstructured-python-library/
To handle such unstructured data, I’ve found the unstructured Python library to be extremely useful. It’s a flexible tool that works with various document formats, including Markdown, , XML, and HTML documents.
What I’m reading today.
Here’s a great quick start guide to getting Jupyter Notebook and Lab up and running with the Miniconda environment in WSL2 running Ubuntu. When you’re finished walking through the steps you’ll have a great data science space up and running on your Windows machine.
I am going to explain how to configure Windows 10 and Miniconda to work with Notebooks using WSL2
The longer holiday weekend edition.
What I’m reading today.
What I’m reading today.
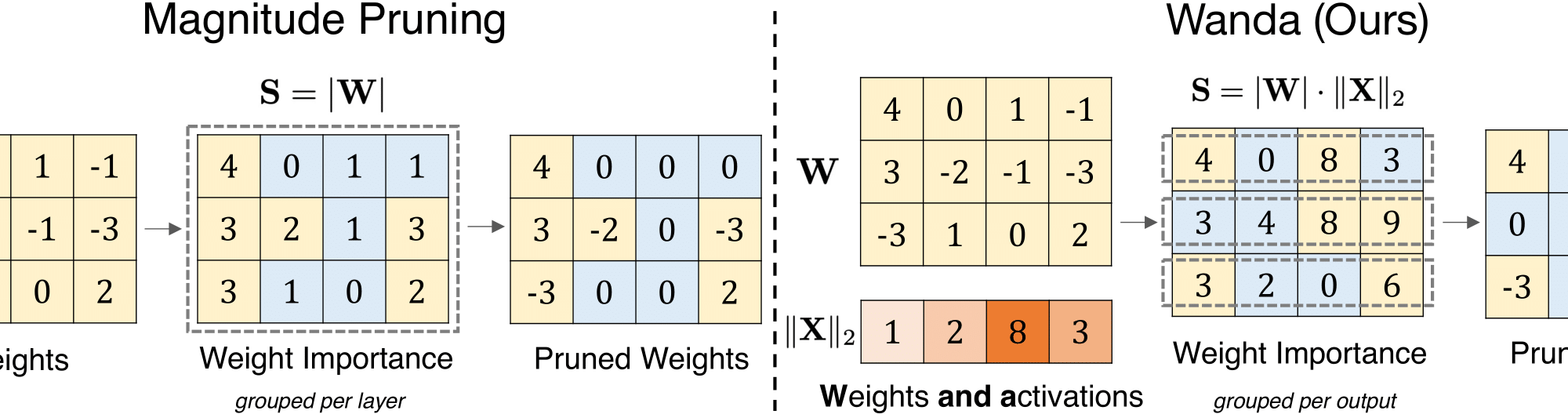
Large language models (LLM) are notoriously huge and expensive to work with. An LLM requires a lot of specialized hardware to train and manipulate. We’ve seen efforts to transform and quantize the models that result in smaller footprints and models that run more readily on commodity software but at the cost of performance. Now we’re seeing efforts to make the models smaller but still perform as well as the full model.
This paper, A Simple and Effective Pruning Approach for Large Language Models, introduces us to Wanda (Pruning by Weights and activations). Here’s the synopsis:
As their size increases, Large Languages Models (LLMs) are natural candidates for network pruning methods: approaches that drop a subset of network weights while striving to preserve performance. Existing methods, however, require either retraining, which is rarely affordable for billion-scale LLMs, or solving a weight reconstruction problem reliant on second-order information, which may also be computationally expensive. In this paper, we introduce a novel, straightforward yet effective pruning method, termed Wanda (Pruning by Weights and activations), designed to induce sparsity in pretrained LLMs. Motivated by the recent observation of emergent large magnitude features in LLMs, our approach prune weights with the smallest magnitudes multiplied by the corresponding input activations, on a per-output basis. Notably, Wanda requires no retraining or weight update, and the pruned LLM can be used as is. We conduct a thorough evaluation of our method on LLaMA across various language benchmarks. Wanda significantly outperforms the established baseline of magnitude pruning and competes favorably against recent methods involving intensive weight update. Code is available at this https URL.
As noted the code behind that paper is readily available on Github at https://github.com/locuslab/wanda for everyone to try.
I think these advances in working with large language models are going to make it more economical for us to host our models and incorporate various NLP and deep learning techniques into our work.
One can use this notebook to build a pipeline to parse and extract data from OCRed PDF files. Warning: When using LLMs for entity extraction, be sure to perform extensive quality control. They are very susceptible to distracting language (latching on to text that sound “kind of like” what you’re looking for) and missing language (making up content to fill any holes), and importantly, they do NOT provide any hints to when they may be erroring. You need to make sure random audits are part of your workflow! Below we’ve worked out a workflow using regular expressions and LLMs to parse data from zoning board orders, but the process is generalizable.
https://github.com/colarusso/entity_extraction/blob/main/PDF%20Entity%20Extraction%20with%20Regex%20and%20LLMs.ipynb
Collect a set of PDFs
Place OCRed PDFs into the data folder
Write regexes to pull out data
Write LLM prompts to pull out data
A Jupyter notebook to extract data from PDFs. Useful stuff