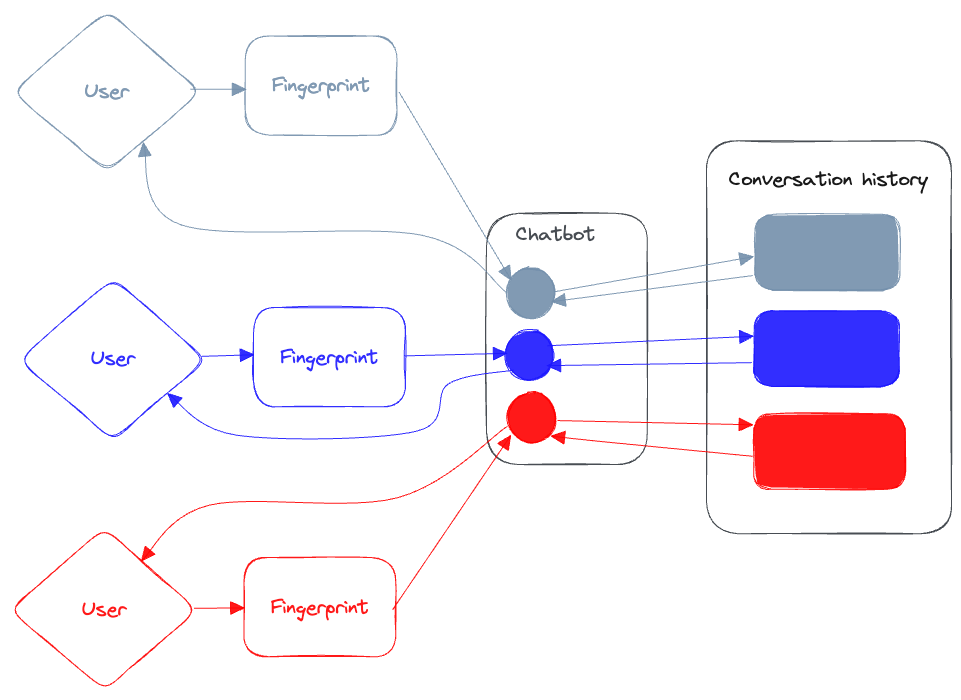
Goal: better, more focused search for www.cali.org.
In general the plan is to scrape the site to a vector database, enable embeddings of the vector db in Llama 2, provide API endpoints to search/find things.
Hints and pointers.
- Llama2-webui – Run any Llama 2 locally with gradio UI on GPU or CPU from anywhere
- FastAPI – web framework for building APIs with Python 3.7+ based on standard Python type hints
- Danswer – Ask Questions in natural language and get Answers backed by private sources. It makes use of
- PostgreSQL – a powerful, open source object-relational database system
- QDrant – Vector Database for the next generation of AI applications.
- Typesense – a modern, privacy-friendly, open source search engine built from the ground up using cutting-edge search algorithms, that take advantage of the latest advances in hardware capabilities.
The challenge is to wire together these technologies and then figure out how to get it to play nice with Drupal. One possibility is just to build this with an API and then use the API to interact with Drupal. That approach also offers the possibility of allowing the membership to interact with the API too.