Large language models (LLM) are notoriously huge and expensive to work with. An LLM requires a lot of specialized hardware to train and manipulate. We’ve seen efforts to transform and quantize the models that result in smaller footprints and models that run more readily on commodity software but at the cost of performance. Now we’re seeing efforts to make the models smaller but still perform as well as the full model.
This paper, A Simple and Effective Pruning Approach for Large Language Models, introduces us to Wanda (Pruning by Weights and activations). Here’s the synopsis:
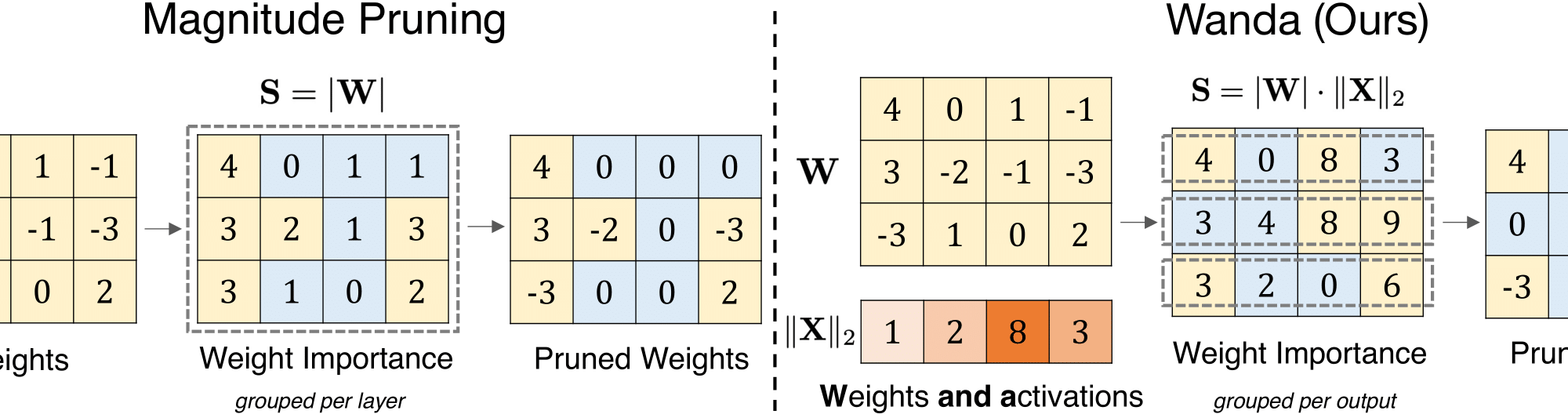
As their size increases, Large Languages Models (LLMs) are natural candidates for network pruning methods: approaches that drop a subset of network weights while striving to preserve performance. Existing methods, however, require either retraining, which is rarely affordable for billion-scale LLMs, or solving a weight reconstruction problem reliant on second-order information, which may also be computationally expensive. In this paper, we introduce a novel, straightforward yet effective pruning method, termed Wanda (Pruning by Weights and activations), designed to induce sparsity in pretrained LLMs. Motivated by the recent observation of emergent large magnitude features in LLMs, our approach prune weights with the smallest magnitudes multiplied by the corresponding input activations, on a per-output basis. Notably, Wanda requires no retraining or weight update, and the pruned LLM can be used as is. We conduct a thorough evaluation of our method on LLaMA across various language benchmarks. Wanda significantly outperforms the established baseline of magnitude pruning and competes favorably against recent methods involving intensive weight update. Code is available at this https URL.
As noted the code behind that paper is readily available on Github at https://github.com/locuslab/wanda for everyone to try.
I think these advances in working with large language models are going to make it more economical for us to host our models and incorporate various NLP and deep learning techniques into our work.