
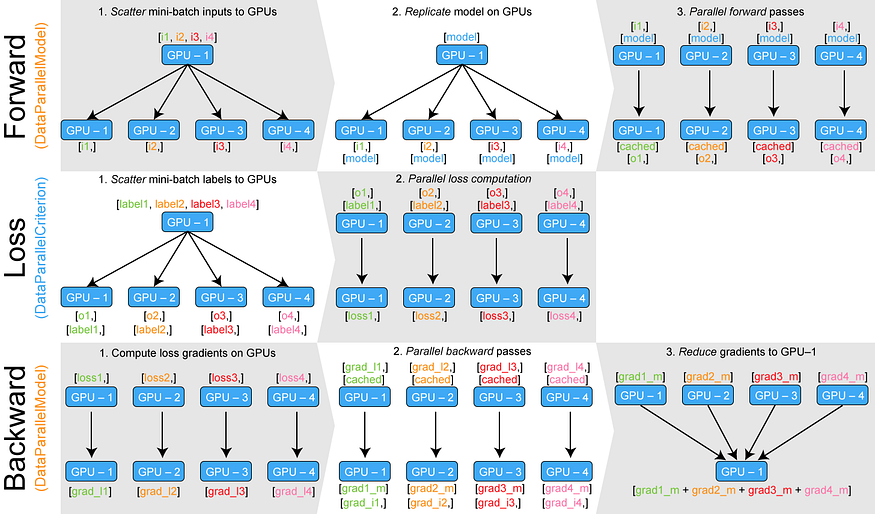
Training neural networks with larger batches in PyTorch: gradient accumulation, gradient checkpointing, multi-GPUs and distributed setups…
Learning Something New: Understanding Long Short Term Memory Networks
LSTMs are explicitly designed to avoid the long-term dependency problem. Remembering information for long periods of time is practically their default behavior, not something they struggle to learn!
Source: Understanding LSTM Networks — colah’s blog
I wonder what would happen if one trained an LSTM network with a couple million court opinions plus code and regulations. Would it be able to answer even a simple legal question?